DATA MANAGEMENT
What does It take to store zettabytes of data?
Exponential data growth is a significant challenge for modern enterprises. According to analyst firm IDC, “on average, enterprises have indicated to IDC that they expect their stored data to grow 30% annually.”1 When we look at just unstructured data, the growth rate jumps up to 50% each year, according to Gartner. Furthermore, Gartner predicts that by 2026, large enterprises will triple their unstructured data capacity stored as file or object storage on-premises, at the edge, or in the public cloud, compared to 2022.
The fact is that enterprises are creating and storing more data than ever before due to ongoing pressure to digitize operations and workflows, generate more metrics to make “data driven” business decisions, and retain data for longer periods of time due to increasingly stringent data security and privacy regulations. This confluence of factors is redefining the way that organizations look at their data storage solutions and the value they expect from an infrastructure service.
Why is so much data being generated? Where is it coming from?
Let’s look at a few more statistics to understand not just the growth of enterprise data, but also the raw capacity of data we’re dealing with. IDC estimates the “Global StorageSphere” – the total installed base of stored capacity – reached 7.9 zettabytes (ZB) in 2021, and will grow at a compound annual growth rate of approximately 19% through 2025.2 That equates to more than 16ZB of stored capacity by 2025. Similar analysis presented by Horison Information Strategies forecasts we’ll reach 11.7ZB of stored data by 2025. Averaging these two figures together gives us 13.9ZB as a conservative estimate which encompasses both data points.
Zettabyte-scale estimates are massive figures that are difficult to conceptualize, so let’s try to make them more relatable. As of 2018, the US Library of Congress stored 16PB of data, or 0.000016ZB. Online sources estimate that YouTube stores approximately 10 exabytes (EB) of data – that’s 0.01ZB. In terms of data creation, your average Zoom video recording creates 200MB of stored capacity per hour. Twitter says it processes multiple petabytes of data daily (although not all of it will be stored). And it is reported that autonomous vehicles will generate as much as 40 terabytes of data an hour when operating. Hopefully these examples provide context regarding the massive amount of stored capacity being generated worldwide.

How can all this data be stored? Cloud object storage and the value of active archiving
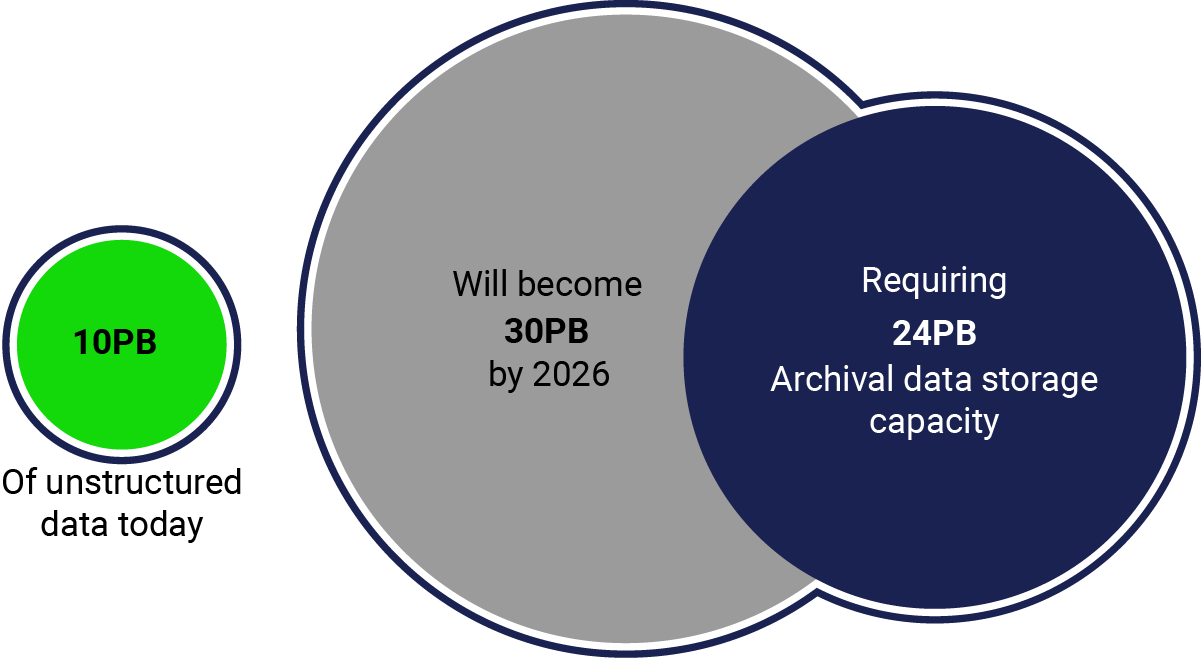
We’ve established the fact that enterprise data and storage volumes are growing exponentially. Using Gartner’s prediction for unstructured capacity growth, we can assume that an organization storing 10PB of unstructured data today should plan to expand their footprint to 30PB of stored data by 2026. Furthermore, organizations should expect to archive 80% of this stored data for long-term retention. That equates to 24PB of archival data which is infrequently accessed (once a month or less). This sounds straightforward, but how realistic is it for enterprises to execute this type of infrastructure expansion and data retention strategy? In most cases, their IT infrastructure budgets are certainly not growing in the double-digits. How can organizations realistically address this challenge?
This is where things start to get interesting. Over the past several years, cost-optimized cloud object storage services have emerged as an essential part of the data archiving and storage management equation. These services can deliver immediate value to organizations by helping them offload stored capacity to a more cost-effective tier, while keeping the data connected and accessible so it can be leveraged as needed, complementing an organization’s primary storage environment. This is often referred to as an “active archive” strategy. Keeping you cloud archive data connected and accessible means this capacity can also act as a foundation for a range of higher-level solutions that extend beyond infrastructure. Examples include integrated backup and disaster recovery services from a third party, distributed global file system solutions which tier data to object storage for long-term retention, or SaaS-based collaboration applications which can leverage low-cost object storage as an access tier.
These types of secondary storage use cases will only become more important over time. As organizations collect more data, they simply aren't able to extract all of its potential value at a single point in time. Enterprises understand that some of their data's value is recognizable immediately, but they also understand that data has potential to be valuable for future business endeavors, workflows, or analysis. Cost-effective cloud storage services help organizations address this uncertainty – allowing them to save more data over longer periods of time so they can capitalize on the “undiscovered” value of their data.
Embracing the inevitable
All signs point to a future of continued, exponential data growth within modern organizations, but that isn’t a reason to despair. Challenges and requirements associated with mass data growth are changing the way that organizations approach their infrastructure and storage strategies – creating the expectation that solutions and services should be low-cost, scalable, resilient, transparent, and accessible in order to meet modern data management requirements. We contend that cloud object services are a key piece of this puzzle, giving organizations access to massively scalable volumes of unstructured storage which is unparalleled in terms of operational cost and global distribution.
For those who are still doubtful, you may be able to take comfort in the fact that the enterprise storage market is constantly evolving. As data volumes grow, new innovations in the underlying media, systems, and software layers will unlock price/performance dynamics that are simply not possible today. Consider the performance benefits possible when object stores can cost-effectively leverage more performant flash and NVM media. And it may seem like science-fiction, but mass capacity improvements promised by novel media like DNA- and silica-based storage are on the horizon, with the potential to upend what we view as “normal” in terms of storage economics.
Sources
IDC, Worldwide Public Cloud Infrastructure as a Service Forecast, 2022-2026, doc #US49520222, August 2022
IDC, Worldwide Global StorageSphere Forecast, 2022-2026: An Installed Base of 7.9ZB of Storage Capacity in 2021 Came at a Cost of $370 Billion – is it Enough?, doc #US49051122, May 2022
Related article

Most Recent
UBX runs the world’s largest boxing franchise, with over a...
How do we build technology budgets amidst an environment where...
In Part 1 of this series, we made the case...
SUBSCRIBE
Storage Insights from the Storage Experts
Storage insights sent direct to your inbox.